...
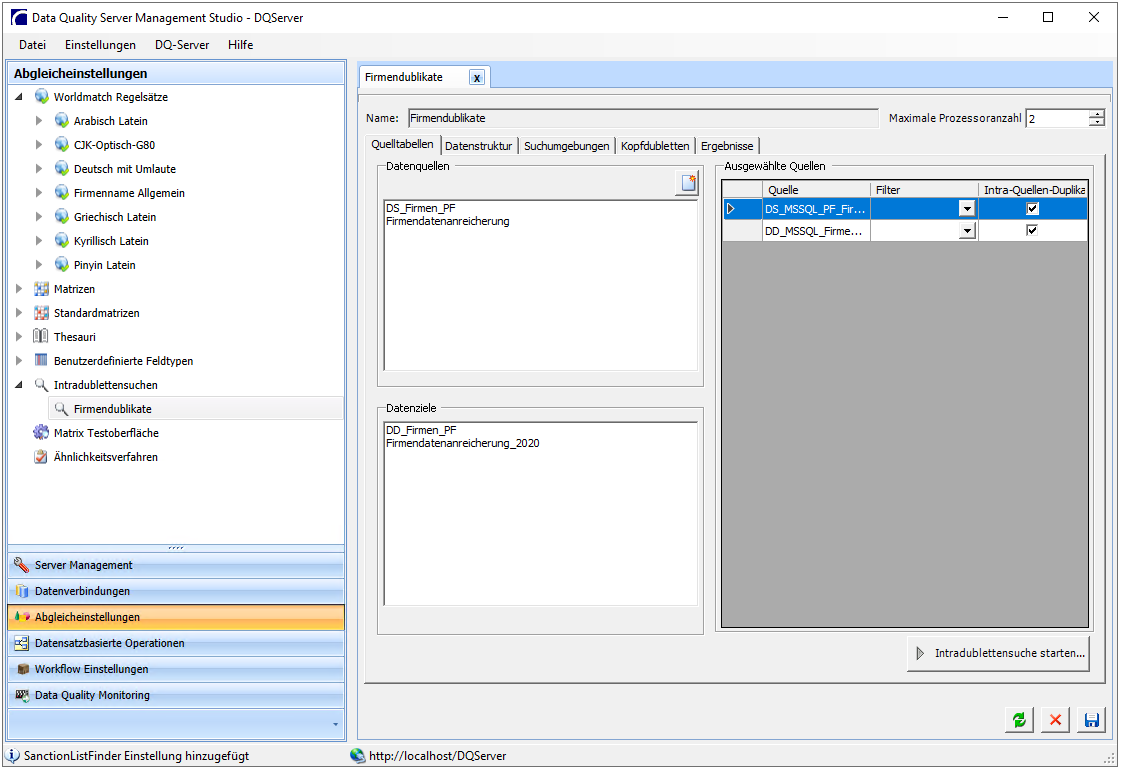
- Hier werden Ihnen bereits angelegte Datenquellen und Datenziele zur Auswahl angezeigt. Per Drag & Drop oder Doppelklick lassen sich diese in den Abgleichbereich „Ausgewählte Datenquellen“ überführen.
Mit dem Button lassen sich Datenquellen auch direkt aus diesem Dialog anlegen. (siehe Datenquellen anlegen)
lassen sich Datenquellen auch direkt aus diesem Dialog anlegen. (siehe Datenquellen anlegen) - Sie haben weiterhin die Möglichkeit mit bereits erstellten Filtern die Datenfelder zur Verarbeitung zu begrenzen.
- Mit der Checkbox Intra-Quellen_Duplikate? legen Sie fest, ob die Datei für den Dublettenabgleich innherhalb innerhalb der Quelle herangezogen werden soll.
...
- Reiter Kopfdubletten
Eine Adresse kann mehrmals innerhalb eines Datenbestandes vorkommen. Werden zwei oder mehr gleiche Adressen (Duplikate) gefunden, werden damit Dublettengruppen gebildet.
Nach dem Adressenabgleich in der Dublettengruppe wird nur eine der Adressen als Kopfdublette, alle anderen als Folgedubletten bewertet. Der bereinigte Datenbestand soll schließlich nur Kopfdubletten enthalten, alle Folgendubletten sollen gelöscht werden.
Um die Entscheidung zu treffen, welche Adresse als Kopfdublette angesehen wird, verfügt der Data Quality Server über unterschiedliche Methoden.
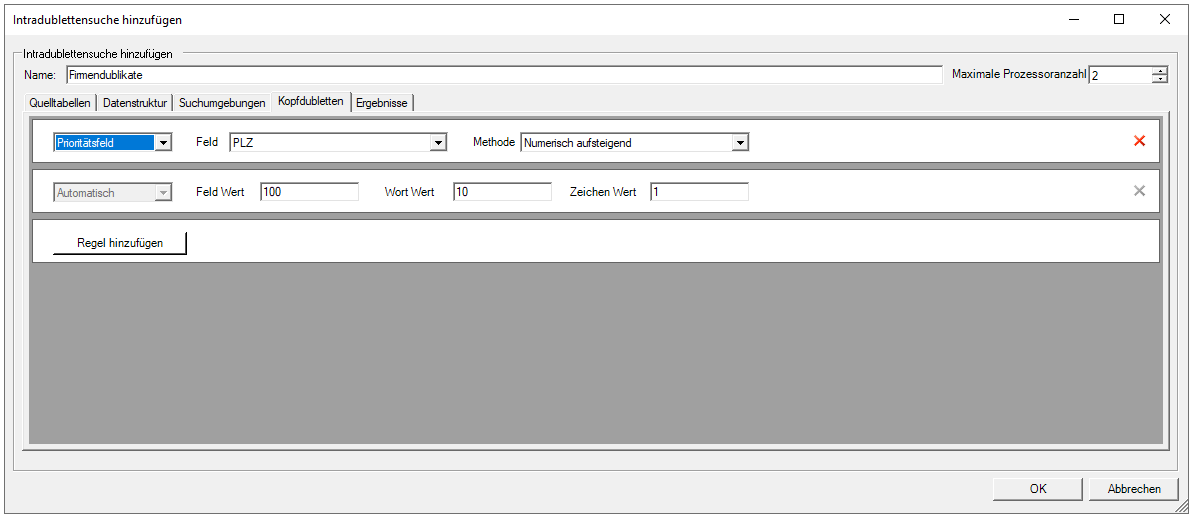

- Methode Automatisch: Per Standard wird die Omikron-Automatik verwendet, welche die Kopfdublette nach der Menge an vorhandenem Inhalt (es werden Punkte für die Menge an befüllten Feldern, die Anzahl der Strings und Zeichen vergeben) in den Feldern des Datensatzes auswählt.
Die Punktwerte können beliebig angepasst werden.
Mit dem Button ![]() können Sie nun weitere Prioritätsregeln für Kopfdubletten erstellen. Die neue Regel erscheint automatisch an Platz eins der Liste der Regeln, die Regeln werden nach Reihenfolge bearbeitet.
können Sie nun weitere Prioritätsregeln für Kopfdubletten erstellen. Die neue Regel erscheint automatisch an Platz eins der Liste der Regeln, die Regeln werden nach Reihenfolge bearbeitet.
Jede weitere neu erstellte Regel wird immer an Platz eins erscheinen.
Sie haben die Möglichkeit unter drei verschiedenen Priorisierungsregeln zu wählen
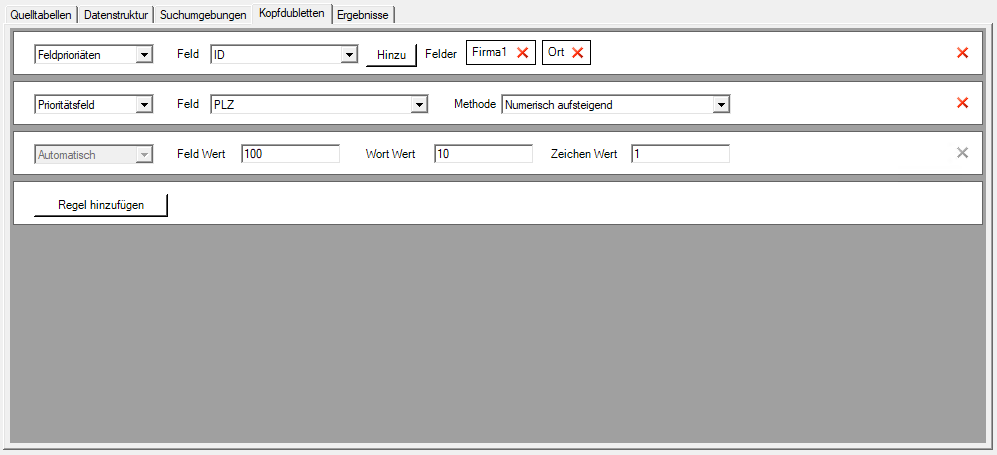
- Prioritätsfeld: Hier wählen Sie ein Feld der Datenstruktur Methode Prioritätsfeld: Diese Methode wählt ein Feld aus, dessen Einträge priorisiert werden. Es wird dann jeweils derjenige Datensatz zur Kopfdublette, bei dem der Inhalt des priorisierten Feldes der Prioritätsmethode entspricht, .
z.B. Feld "PLZ" Methode „Nummerisch aufsteigend“.

Als Methoden stehen folgende Sortierungskriterien zur Verfügung:
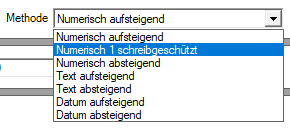
Anmerkung: "Text aufsteigend" bzw. "Text absteigend" entspricht einer alphabetischen Sortierung.
- Feldprioritäten: Wählen Sie Methode Feldprioritäten: Diese Methode wählt ein oder mehrere Felder der Datenstruktur aus, die Einträge enthalten sollen. Es wird dann jeweils derjenige Datensatz zur Kopfdublette, bei dem die benannten Felder Inhalte haben, wenn dies in dem anderen Datensatz nicht der Fall ist.

Wählen Sie hierzu ein Feld aus dem Dropdown aus und Klicken auf ![]() . Mit
. Mit ![]() können Sie einen Feldeintrag wieder löschen.
können Sie einen Feldeintrag wieder löschen.

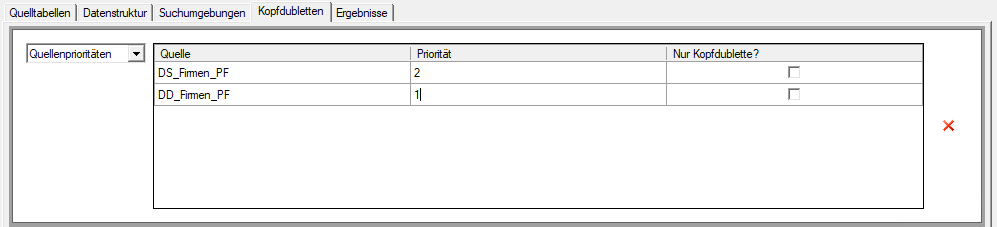
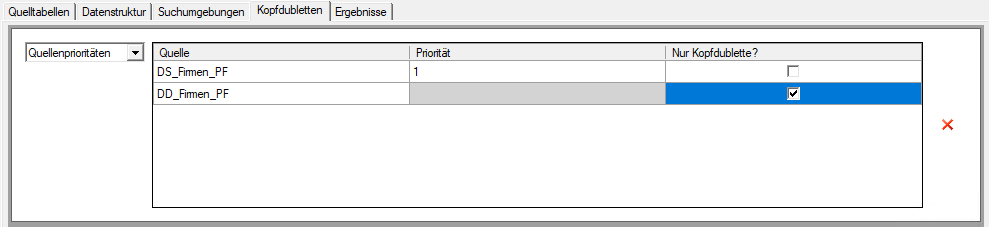
- Quellprioritäten: Wählen Sie hiermit, die Felder welcher Datenquelle immer als Kopfdublette gelten sollen. Es wird dann jeweils derjenige Datensatz zur Kopfdublette, der aus der Priorisierten Datenquelle stammt.
- Sie können eine Priorität
- per numerischer Sortierung je Datenquelle eingeben
- per Checkbox Nur Kopfdubellte? bestimmen, welche Datenquelle herangezogen werden soll
- Sie können eine Priorität
Mit ![]() können Sie eine ganze Regel wieder löschen.
können Sie eine ganze Regel wieder löschen.
Diese Methoden können auch kombiniert werden, wobei von oben nach unten überprüft wird, ob die Methode im speziellen Fall eine Entscheidung bringt. Wenn dies nicht der Fall ist, wird die darunterstehende überprüft.

Reiter Ergebnisse
Hier definieren Sie den Export Ihrer Ergebnisse. Ausgangsbasis ist dabei die Datenstruktur, welche im Reiter Datastructure definiert wurde. Außerdem werden noch die Statusfelder ergänzt, welche durch die Dublettenprüfung neu entstehen.

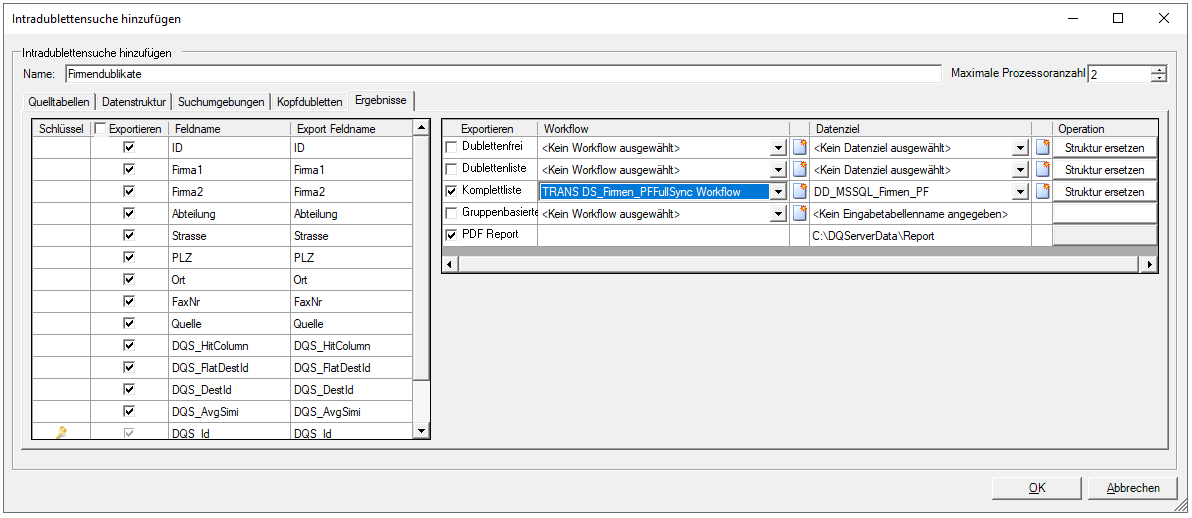
- DQS_HitColumn: Dieses Feld enthält die Position der Matrixspalte, welche die Dublette gefunden hat (1 für die erste Spalte, 2 für die zweite usw. – die Kopfdublette hat den Wert Head).
- DQS_DestId: Dieses Feld enthält die ID des Datensatzes, der direkte Kopfdublette ist – aufgrund der Baumstruktur der Dublettenabhängigkeiten ist das nicht zwangsläufig die Kopfdublette der zugehörigen Dublettengruppe, sondern evtl. eine der anderen Folgedubletten.
- DQS_FlatDestId: Dieses Feld enthält die ID der zugehörigen Dublettengruppe – gleichzeitig die ID der Kopfdublette.
- DQS_AvgSimi: Dieses Feld enthält einen durchschnittlichen Ähnlichkeitswert zwischen Folgedublette und direkter Kopfdublette.
...
- Exportieren als PDF Report: Es wird ein Report mit Statistiken der Analyse im PDF-Format exportiert. ACHTUNG: Achten Sie darauf, dass der DQ Server Schreibrechte im angegebenen Pfad besitzt.
![]()
![]()