Betriebszenarien
Die drei FACT-Finder Anwendungen können auf einem oder unterschiedlichen Servern betrieben werden, je nach Shopgröße und Anspruch ist daher ein anderes Betriebsszenario sinnvoll. In allen Fällen müssen die Anwendungen jedoch Daten untereinander austauschen können und die grundlegende Installation der Systeme unterscheidet sich nicht.
Die Bezeichnung Server ist als Umgebung bzw. System zu verstehen, es ist nicht notwendig, dass es sich bei diesen um Bare-Metal-Server handelt.
Alle drei Anwendungen auf einem Server
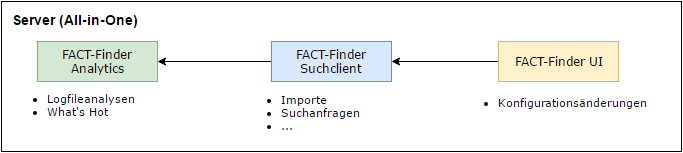
Das einfachste Szenario ist die Installation aller drei Anwendungen auf einem Server, da hier nur ein System eingerichtet und betrieben werden muss. Auch muss man sich in diesem Fall keine Gedanken um den Transfer von Dateien zwischen den Systemen und deren Berechtigungen machen. Dieser Vorteil ist gleichzeitig auch der größte Nachteil, da sich die Systeme gegenseitig beeinflussen können. Falls beispielsweise eine rechenintensive Analyse gestartet wird, könnte sich das negativ auf die Performance der Suchanwendung auswirken.
Weil sich die Installation der Server je Anwendung nicht unterscheidet, nimmt diese Anleitung dieses Betriebsszenario an. Besonderheiten der anderen Szenarien werden jedoch in speziellen Kapiteln erläutert.
FACT-Finder Analytics auf einem getrennten Server
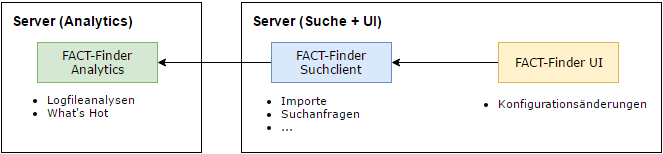
In diesem Szenario wird Analytics auf einem eigenen System betrieben, so dass dieses den Produktivbetrieb der Suche nicht beinflussen kann. Für den Großteil der Kunden ist dies erfahrungsgemäß die sinnvollste Variante.
Der Betrieb dieser Variante hat die Besonderheit, dass der Zugriff der Analytics-Anwendung auf die Logfiles der Suche sichergestellt werden muss. Die Suchanwendung benötigt die entsprechenden Logfiles am Folgetag nicht mehr, so dass diese grundsätzlich in einem, z.B. nächtlichen, Job von einem System auf das andere verschoben werden können, um so Speicherplatz auf dem Suchsystem freizuräumen. Alternativ ist es natürlich auch möglich einen gemeinsamen Netzwerkspeicher zwischen den beiden Servern zu nutzen.
Alle drei Anwendungen auf getrennten Servern
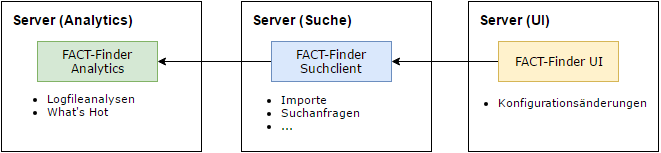
In diesem Betriebsszenario hat, neben der Analytics-Anwendung, auch die UI einen eigenen Server. Daher gelten auch die Hinweise des vorhergehenden Szenarios bezüglich des Datentransfers von der Suchanwendung an Analytics.
Der Vorteil dieser Variante ist, dass das Serversizing besser an die unterschiedlichen Anwendungen angepasst werden kann und man die Komponenten getrennt hat, um ggf die Suchanwendung später einfacher duplizieren zu können womit beispielsweise ein Staging-System oder Lastverteilung möglich ist. Da die UI-Anwendung mit den anderen beiden Systemen nur über APIs kommuniziert und keine Daten der anderen Anwendungen benötigt, lässt sich dieser Teil auch relativ einfach abtrennen.
Der Nachteil ist eine etwas höhere Laufzeit zwischen der UI und dem Suchclient.
Betrieb von mehreren Suchanwendungen
Wie schon erwähnt liegt die Business Logik von FACT-Finder in der Suchanwendung. Ist es daher gewünscht oder notwendig, die Last auf mehrere Systeme zu verteilen oder zum Live-System auch ein Test- oder Staging-System zu betreiben, muss diese Anwendung vervielfältigt werden. Mehrere UI- und Analytics-Anwendungen sind hierfür nicht notwendig.
Staging Anwendung
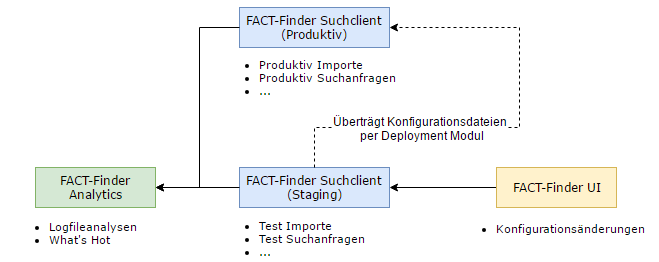
Sollten Sie eine Stagingumgebung wünschen, in der Sie beispielsweise Suchkonfigurationen vor der Live-Setzung testen, ist der Aufbau der Anwendungen wie im oberem Schaubild. Da Sie nur Änderungen auf der Staging-Suchumgebung durchführen, muss die UI-Anwendung auch nur an diese angeschlossen werden.
Das Übertragen der Konfigurationen können Sie entweder über die eingebaute Deployment-Funktionalität oder eine Synchronisation der Ressourcenverzeichnisse, beispielsweise über rysnc, bewerkstelligen. Falls Sie das Deployment-Feature verwenden wollen, müssen beide Suchanwendungen auf unterschiedlichen Ports betrieben werden und gemeinsamen Zugriff auf Festplattenspeicher besitzen. Sollten Sie die Ressourcenverzeichnisse synchronisieren wollen, so können Sie die Logfiles ausschließen. Sollten beide Instanzen zusätzlich über andere Datenbestände verfügen, müssen zusätzlich auch die Exportdaten und die Suchdatenbank davon ausgenommen werden.
Lastverteilung
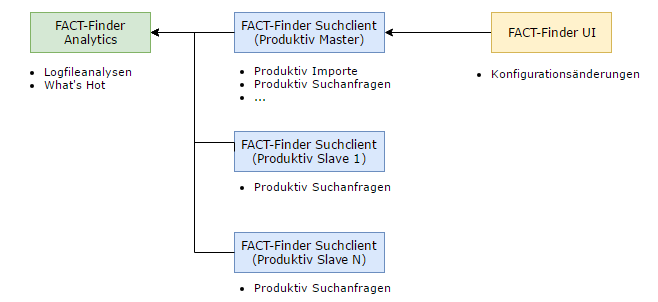
Wollen Sie die Suchanfragen von mehreren Suchanwendungen bearbeiten lassen, so entspricht der Aufbau dem oberen Schaubild. Sie können zusätzlich auch noch weitere Anwendungen, z.B .wie im Diagramm zuvor eine Stagingumgebung, in dieses Szenario einbauen, so dass sich die Aufgaben der Instanzen unterscheiden. In diesem Fall müssen Sie darauf achten welche Daten Sie zwischen welchen Systemen übertragen bzw. synchron halten.
Eine Instanz im Verbund ist ihre Masterumgebung, ob diese produktiv oder als Stagingumgebung betrieben wird ist Ihnen überlassen. An diese Instanz schließen Sie die UI-Anwendung an und von dieser Instanz werden die Ressourcen an die anderen Slave-Instanzen verteilt. Dies kann prinzipiell auch über einen gemeinsam genutzten Netzwerkspeicher umgesetzt werden. Da alle die gleichen Suchdatenbanken nutzen, ist es nur notwendig, dass eine Instanz aus dem Verbund importiert und die Datenbanken den anderen zur Verfügung stellt, so dass die Importlast nicht auf allen Systemen anfällt. Während des Importes kann bei Bedarf die entsprechende Instanz aus dem Lastverteilungs-Verbund genommen werden oder weniger Suchanfragen zugeteilt bekommen um das System nicht zu überlasten.
Vor die Produktiv-Suchclients wird ein Loadbalancer geschalten, der die Anfragen entsprechend verteilt. Bei Nutzung des Personalisierungsmoduls muss dies im Sticky-Sessions-Modus passieren.